if __name__ == '__main__':
f = open('test.dat','rb')
bit_pos = 0
start_pos = sys.maxint
analize_data = ""
for line in f:
for s in line:
bit = struct.unpack('B',s)[0]
hex = "%02X" % bit
if bit_pos == 1:
start_pos = int(hex, 16)
if start_pos <= bit_pos:
analize_data += hex
bit_pos += 1
print analize_data
f.close()
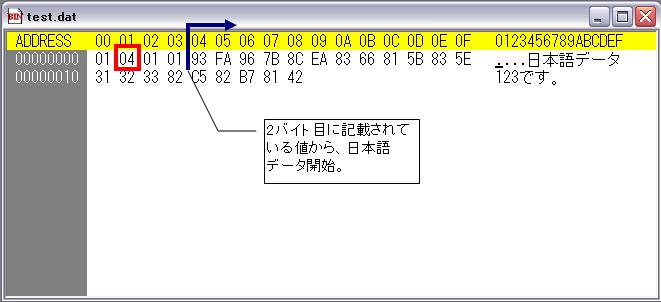
プログラムを実行すると、
> 93FA967B8CEA8366815B835E31323382C582B78142
日本語が保存されている領域のデータが取得できました。
と、ここまでは良かったのですが、この文字列を日本語に直すには・・・
ちょっと微妙ですが、私はこんな感じのコードを書いて、日本語を取得しました。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import struct
import sys
def to_string(value):
#一バイト目が128以下は英数?
result = ""
carry = ""
for i in range(0,len(value),2):
v = value[i:i+2]
if len(carry) != 0:
v = carry + v
carry = ""
result += struct.pack(">H",int(v,16))
else:
if int(v,16) < 128:
result += struct.pack("B",int(v,16))
else:
carry = v
return result
if __name__ == '__main__':
f = open('test.dat','rb')
bit_pos = 0
start_pos = sys.maxint
analize_data = ""
for line in f:
for s in line:
bit = struct.unpack('B',s)[0]
hex = "%02X" % bit